
AWS RDS je skvělá služba, nicméně trochu rozpapaná. Dnes bych Vám rád pověděl příběh s (NE)šťastným koncem. O tom, jak se dá v AWS ušetřit až 30% rozpočtu (nebo naopak propálit).
Webinář zdarma: Jak na sociální sítě, aby to mělo skutečně návratnost?
Právě za chvíli začíná náš webinář zdarma, ve kterém vám ukážu, proč 97 % podnikatelů dělá na Facebooku chyby, kvůli kterým prodělávají peníze a jak se těmto chybám vy vyhnete. Tak honem, ať vám to dnes neuteče!


Možná si vzpomenete na článek Jak jsme rozstřelili Collabim z ledna letošního roku. Ten vysvětloval, jak jsme se během měsíce dostali z jedné databáze na sedmou. I Vašemu pejskovi musí být jasné, že se tento krok neobešel bez dodatečných nákladů.
A právě ekonomická analýza provozu našeho projektu Collabim v AWS ukázala poměrně velké možnosti úspory v našem měsíčním rozpočtu právě v oblasti RDS.
Pojďme si tedy povyprávět příběh pěkně od začátku.
Analýza nákladů AWS RDS
Začalo to vcelku nevinně. Přišel účet od Amazonu a po půl roce se na něj někdo konečně podíval. Vykazoval totiž známky až hanebné útraty. Prakticky téměř 2,5x více od doby, co jsme Collabim převzali v roce 2016.


To už se ale v našich hlavách sepla kontrolka, že něco není úplně ok.
Pustili jsme se tedy do podrobnějšího zkoumání. Poměrně záhy se ukázalo, že velký nárůst mělo na svědomí testování nové struktury našich serverů pro scrape (získávání dat) paralelně se stávající srukturou a další dočasné pokusy o vyšší výkon našeho systému.
Co ale upoutalo pozornost, byl enormní nárůst u RDS (databáze jako služba).
Ze 171 USD/měsíc v únoru 2016 do června 2019 jsme se rozšoupli na 624 USD/měsíc. To je více než 3,6x!
Ekonomická úspora migrace na EC2
Netrvalo dlouho a měli jsme na stole hezký výpočet.
Pokud bychom zmigrovali všechny DB, které jsme v posledním roce kvůli výkonu dávali do RDS na vlastní EC2 instance, ušetřili bychom minimálně 300USD/měsíc. O něco více, pokud bychom se rozhodli být střelci a dát je na spot instance.
Tyto DB nejsou ve většině případů určené přímo na zákaznická data, takže by menší několikahodinový výpadek neměl na aplikaci a uživatelský zážitek prakticky žádný dopad.
Přeci jen provozovat aplikační DB na serverech, které vám může Amazon vypnout z minuty na minutu, je docela odvaha.
Teoretické spouštění vlastní DB na EC2 – krok první
Takže bylo rozhodnuto, musíme to zkusit.
Pro migraci jsme vybrali nejméně podstatnou databázi, která obsahuje pouze našeptané výrazy z vyhledávačů a související hledání. V RDS běží na instanci db.t2.medium (2CPU 4GB RAM), takže proč ji nepustit na tom samém, ale v EC2 – t2.medium.
Ok, odtud je to rutina. Upravit ansible, který používáme na orchestraci celého AWS stacku – tedy přidat nový oddělený playbook pro tuto instanci a jdeme instalovat. Za 15 minut nám už běží instance nakonfigurovaná podle našeho MYSQL cache serveru.
Easy money, jak by řekl klasik.
Teď tam ještě vložit data. Máme tam jen necelých 15GB, tak to bude švanda. Po pár minutách googlení objevujeme AWS migration service, službu určenou k bezvýpadkové migraci databáze odkudkoliv kamkoliv.
Služby AWS nás neustále překvapují, mají tooly snad na cokoliv, co můžete v praxi potřebovat. Stačí jen googlit.
Migrace první DB v praxi – použití AWS migration service
Konfigurace této služby už je trochu oříšek. Přeci jen jsme frajeři a manuály jsou pro zbabělce.
Takže metoda pokus omyl a po hodině a půl už nám data proudí přímo z RDS na novou EC2 instanci.
18 minut a je hotovo. To byl šupec.
Měníme nastavení konfigurace v naší aplikaci na tento nový server a pouštíme nový deploy. Neuvěřitelné, na první dobrou a vše běží jak má. Teda alespoň si to myslíme 😀
Migrace druhé, o trochu větší DB v praxi a hodinový downtime celé aplikace
Posilněni úspěchem první migrace jsme se tedy rovnou vrhli na druhou o něco větší DB – 52 GB. Tato databáze už je trochu důležitější, při jejím kompletním výpadku to odnese i aplikace. Pokud je ale prázdná, zákazníci nic nepoznají, stačí aby běžela.
Na pozadí tedy opakujeme stejné postupy z předchozího článku, vše již máme přece vyzkoušené. Tentokrát už ale kopie dat zabrala 1h 57m. Nevadí, workery stály a databáze nebyla krmena daty, takže se nic neděje.
Přepínáme aplikaci na novou EC2 db instanci
Stejně jako v prvním případě vše jede jak má, paráda. Jdeme na sváču.
Bezvýpadkový přechod se povedl i u této větší databáze. A to na celé 3 minuty. A to až do prvního startu workerů, co tuto DB krmí daty. Ale to bychom předbíhali, na toto jsme přišli až po cca 35 minutách.
Problém totiž začal úplně jinde – vypadla aplikace a náš monitoring začal řvát DB error – TOO MANY CONNECTIONS. Jenže na naší hlavní databázi, která obsahuje ta opravdu důležitá zákaznická data.
Zprvu nám vůbec nebylo jasné, co se děje, takže jsme najeli na klasické postupy, které uplatňujeme v podobným případech. Vypnutí workerů, restart aplikačních webových serverů apod.
Zachraňujeme aplikaci
Nic nepomáhá, workery se nechtějí vypnout a stále nám buší do DB. Natvrdo ustřelujeme PHP a pomocí security groups oddělujeme servery od všech DB (a zpět) a voilá, aplikace se rozjíždí.
Pohoda.
Necháváme cca 15 minut odpočinout a znovu najíždíme workery. Stačí jen 2 minuty a situace se opakuje. Boží.
Celý proces opakujeme několikrát s různými obměnami. Bez výsledku.
Po půl hodině výpadku nás konečně napadne – co ta nová databáze, co ta vlastně dělá?
Na SSH serveru se nedá dostat, zajímavé.
Škoda, že přesunem z RDS na EC2 této DB jsme přišli i o velmi detailní monitoring MySQL – Performace Insights. Jinak by totiž stačilo se do nich podívat a okamžitě bychom viděli, co přesně se tam děje.
Problém bude asi na novém serveru, kdo by to byl řekl?
Takto se nedostaneme ani na SSH, ani se k DB nepřipojíme, abychom si vyjeli STATUS přes CLI.
Ok, server restartujeme a vypínáme všechny workery.
Server se restartoval, připojujeme se a díváme se na queries vypálené na tento MySQL server. Zapínáme workery.
Zpočátku nic zvláštního, najednou ale pozorujeme, že i triviální queries trvají extrémně dlouho. Hmm, server není zahřátý, to může být mysql cache. Ale ani 5 minut po startu žádné zlepšení, na SSH se opět nedá dostat.
Snad již ve školce se všichni programátoři učí základ relačních databází. Indexy. Raději se přesvědčíme, že kolega, který dával DB dohromady, na tento základ nezapomněl a jen náhodou to do dnešního dne jelo. Přeci jen jedeme na jiném stroji než v RDS.
Indexy komplet chybí, přítomný je pouze hliník (tedy primární indexy)
Cože? To není možné. Šup na RDS do původní DB. Hele, tady jsou.
EC2 zmigrovaná DB – tady ne, jsou tu jen primární. A to může být problém, který vyřešíme později. Teď rychle zpět přepnout aplikaci na RDS.
Skoro po hodině aplikaci opět jede.
Protože nejsme žádní extra experti, dodnes nám není úplně přesně jasné, co se vlastně stalo. Nicméně teorie zní takto:
V důsledku extrémního záseku queries na EC2 DB při chodu workerů se zabrzdila celá aplikace, zákazníci čekali i na odbavení běžného provozu aplikace (přihlášení apod.) a každý nový uživatel tak zvyšoval zatížení PHP-FPM serveru, který začal škálovat do nebývalých rozměrů, až dosáhl vytížení i hlavní DB.
A tím šla celá aplikace takříkajíc do kopru.
Několikadenní průzkum bojem
Takže po dalších googlení zjišťujeme, že toto nebylo přehlédnutí, ale prostě totální selhání. Absenci indexů totiž AWS u služby migration service přímo popisuje.
Máme tedy nový problém: Jak zmigrovat 52 GB DB tak, abychom to zvládli co nejrychleji, a to včetně indexů?
První pokus o indexaci ex-post moc nefunguje. Jednu tabulku z 10 trvá naindexovat přes 3 hodiny.
Proč nás to ale trápí?
Migrace je jedna věc, ale pro reálný provoz musíme myslet samozřejmě ještě na další scénář. Co když něco selže a budeme muset komplet DB obnovit nejen z binární zálohy, ale také z kompletního SQL dumpu? EC2 snapshoty nám ne vždy totiž fungují na 100%. Někdy se nám stává, že se na zreplikovaný server nedá dostat přes SSH. Proto druhý backup v podobě SQL dumpu.
Jenže dostat tam dump bude asi dost časově náročné. Je tedy třeba vymyslet způsob, jak DB co nejrychleji obnovit do produkčního stavu pouze z nejhorší možné zálohy – čistých SQL queries v dumpu.
Rady na diskuzích hovoří vždy velmi podobně:
- oddělte data a strukturu -> nejprve strukturu, pak indexy, nakonec data
nebo
- oddělte data a strukturu -> nejprve strukturu, pak data, nakonec indexy
nebo
- takto velkou DB nelze pomocí SQL dumpu naimportovat v řádu hodin
Protože si raději vše ověřujeme, tak zkoušíme každou uvedenou možnost.
A internety mají pravdu, fakt to nejde.
Facebook pomáhá
Tak co zkusit sehnat pomoc, s tímto snad musí někdo mít zkušenost.
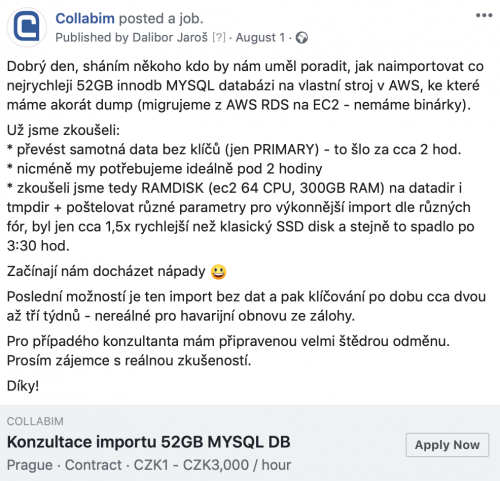
Během dvou dní dvě odpovědi. Super.
Jenže ani jeden nemá přímo radu, jak na to, pouze nabízí, že to „zkusí“. Ok, jeden chce řádově tisíce, druhý se nebojí říct si o 100 000 Kč za nejistý výsledek a už vůbec ne dle zadání (migrace do pár hodin):
![]()
Protože jsme dobří hospodáři, voláme prvního. Po třech dnech máme možná řešení. Odstranit z DB nepotřebné indexy a také partitioning, který tam historicky máme, ale nikdo neví proč.
Zkoušíme tedy upravenou strukturu a následně do ní naládovat data.
Facebook fakt NEpomáhá
Import zdá se funguje. Po cca 7hod. a stavu importu 56% DB padá a musíme zkusit nanovo.
Zkoušíme ještě dvakrát, ale bez výsledku.
A import nakonec řeší…
Po 14 stastiplných dnech (ne na fulltime samosebou) konečně kolegu, který se léta zabýval realitními portály, napadá zajímavá myšlenka: Vypadá na na kombinaci bottlenecku samotné MySQL a pomalého zápisu na disk.
Co zkusit RAMDISK?
Jenže DB má 52GB, spolu s pomocnými cache a dalšími věcmi si vezme i 130GB, při importu možná až dvakrát tolik.
Na AWS ale není problém, největší mašina až 12 TB RAM.

Jdeme tedy do m5.16xlarge – 256 GB RAM a 64 jader snad bude stačit. Za těch pár hodin provozu nás bude stát pár babek (cca 3,5 USD / hodinu).
Nebudu už zdržovat, původní plán, že naimportujeme do finální struktury, se ukázal jako nemožný, a to i na kompletním RAMDISKu jak datadir (data adresář v mysql), tak tmpdir (temp, do kterého si MySQL odkádá data).
Nakonec fungoval perfektně postup, který jsme rovnou na začátku zavrhli. Díky mylné informaci o rychlosti indexace – probíhala totiž pod zátěží a MySQL běžela na klasickém SSD disku.
Finální vítěz:
- nahrání čisté struktury jen s primárními indexy (2 sec.)
- import dat (lehce pod 2 hod.)
- dodatečná indexace pomocí ANSIBLE scriptu (42 min.)
Ansible skript tam byl proto, aby u indexace nemusel nikdo sedět. Jakmile se naindexoval jeden index, poslala se zpráva do SLACKu a rovnou se začal indexovat další. Navíc máme uloženou indexaci pro budoucí já.
Celkový čas importu tedy nakonec zabral necelých 2 hod. a 45 min.
Prozatimní zkušenosti z provozu
Zde však bohužel příběh končí nešťastným koncem.
Během dvou dní zkušebního provozu jsme totiž odhalili, že se nám nepodařilo optimalizovat EC2 instanci tak, aby nevznikaly deadlocky na DB.
A ano, zkopírovali jsme do posledního parametru kompletní nastavení RDS instance. Výkon instance byl stejný, zkoušeli jsme i větší.
Aplikace však vykazovala extrémní množství deadlocků, čímž se DB stala nepoužitelná, a tak jsme byli nuceni se po pár dnech zkoušení vrátit se zpět na RDS.
I tak to někdy končí. Hlavní ale je, že jsme zase o kousek před nimi! 😀
