Jak jste možná zaregistrovali, před asi dvěma lety INIZIO vstoupilo do projektu Collabim.
Webinář zdarma: Jak na sociální sítě, aby to mělo skutečně návratnost?
Právě za chvíli začíná náš webinář zdarma, ve kterém vám ukážu, proč 97 % podnikatelů dělá na Facebooku chyby, kvůli kterým prodělávají peníze a jak se těmto chybám vy vyhnete. Tak honem, ať vám to dnes neuteče!


Díky tomu, že se po technické stránce o tento projekt staráme více než jeden a půl roku, řekli jsme si, že je na čase abychom se s vámi podělili o nějaké zkušenosti také z tohoto projektu, když už na našem blogu čtete o ostatních našich projektech (zejména však v oblasti webové analytiky).
Dnes se podíváme na to, jak jsme přistoupili programátorsky ke zrychlení celé aplikace Collabimu a zpříjemnění uživatelského zážitku našim uživatelům.
Projekt aktivně vyvíjíme, přidáváme nové funkce a pracujeme samozřejmě také na jeho marketingové propagaci -> odměnou je nám růst všech našich uživatelů, především pak těch placených, jak můžete vidět na grafu níže:
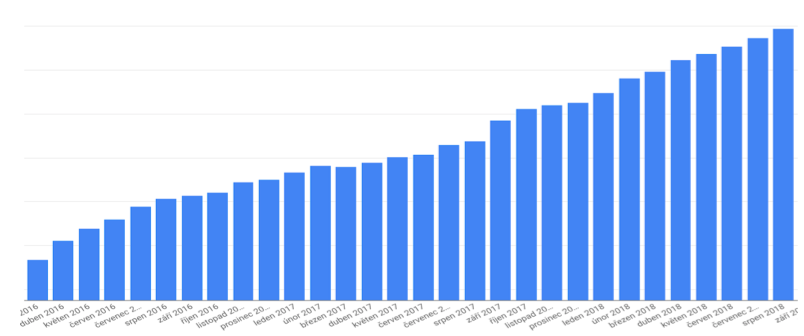
S tím také souvisí stále narůstající obliba jednorázových analýz, které umožňují rychlé ad-hoc zjišťování stavu ať už Vašeho webu, konkurence nebo pozic klíčových slov mimo dennodenně sledované projekty. Graf růstu popularity a používání těchto analýz můžete vidět zde:
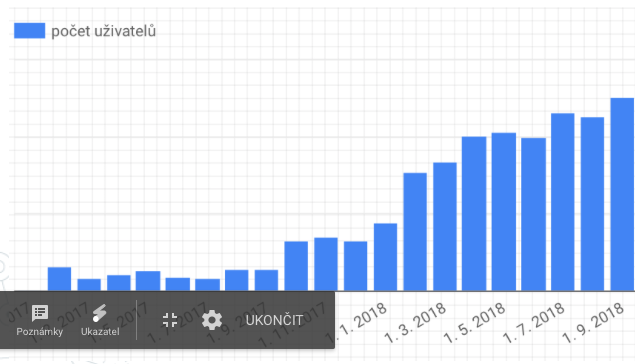
Jak náš nástroj roste a přibývají uživatelé, začali jsme koncem v loňských prázdnin pociťovat problém s rychlostí odezvy celé aplikace, což samozřejmě negativně působilo na naše uživatele a nebylo to zdaleka komfortní. Nemluvě také o tom, že zhoršující se odevzdal aplikace mnohdy skončila vypršením časového limitu pro zobrazení stránky a tím pádem výpadkem.
Jak jsme vůbec přišli na to že máme nějaký problém s rychlostí? Velmi jednoduše – stačilo podívat se do našich GA, které stejně jako vy i my máme nasazené na našem projektu. V sekci rychlost stránek potom vidíte ten krásný kopeček, který se vzhledově blíží výšlapu na jihočeskou Kleť:
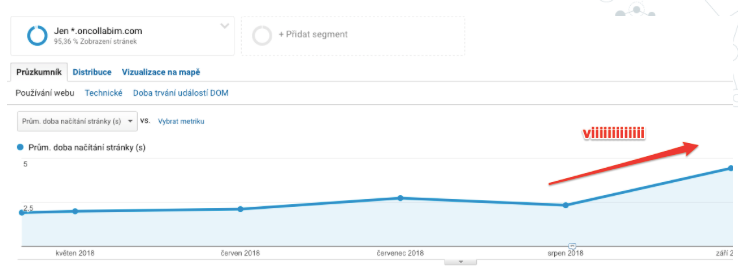
Nutno říci, že první známky toho, že aplikace nestíhá jsme však měli již o několik měsíců dříve. Bohužel jsme je však statečně ignorovali:

Zde se díváte na e-maily, které chodily z našeho monitorovacího systému na Amazon web Services (zkráceně AWS), kde celý projekt hostujeme na několika serverech.
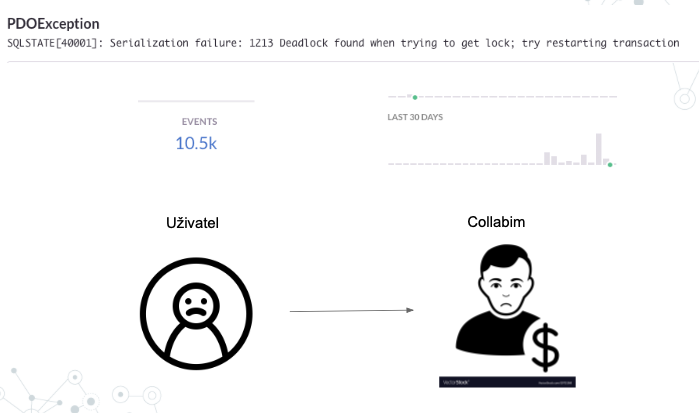
Také náš monitorovací systém na chyby s názvem SENTRY nás již nějakou dobu upozorňoval -> číslo vlevo nahoře (10,5k) bohužel neznačí naše hodinové revenues projektu, ale počet chyb za posledních 30 dní, což ukazuje graf vpravo. Jinými slovy vynechávala databáze a začali jsme dostávat bloky a databáze nestíhala nejen zapisovat, ale ani číst. Díky tomu začal být uživatel smutný, což by však postupem času zapříčinilo, že bychom byli smutní i my a pocítili bychom do toho na tržbách, logicky.
Pojďme se ale nyní podívat na to jak vlastně naše aplikace vypadá. Zde je možno vidět schéma naší aplikace. Není nyní až tak podstatné, co přesně se na schématu vyskytuje, spíše si povšimněte komplexnosti systému:
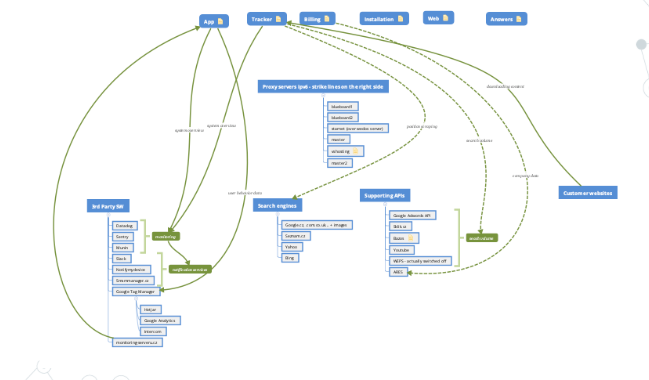
Při návrhu Collabimu a jeho rozvoji se totiž dostatečně myslelo na diverzifikaci jednotlivých služeb, které se o provoz celého systému starají a proto je Collabim rozdělen do několika funkčních bloků, kde každý má svojí úlohu. Například Collabim APP slouží k odbavování uživatelů a je to vlastně ta jediná část Collabimu, kterou uživatel navenek vidí. Collabim Tracker je potom samostatná aplikace sloužící k získávání dat a data mining z internetu. Další jsou potom Collabim billing pro obsluhu fakturace, Collabim mail queue pro posílání e-mailů apod.
V zásadě je patrné, že co se týče rozdělení úkolů, tak je Collabim poměrně daleko. Celá aplikace je pěkně diverzifikovaná a výpadek jedné části neohrožuje choď celého systému.
Následující obrázek však popisuje naše databázové schéma v srpnu 2018:
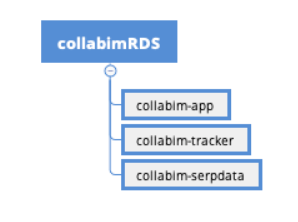
Je vidět, že i zde se při návrhu myslelo na to, že se jednoho krásného dne databáze rozdělí a poběží na samostatných strojích, takže aplikace byla v základě pokryta třemi různými databázemi (nejsou zde znázorněny pomocné aplikace které nejsou kritické pro chod aplikace).
Problémem však bylo, že vše běželo a jednom jediném stroji – respektive protože používáme AWS RDS neboli Remote database Service – což v praxi znamená, že databáze neběží na našem vlastním stroji, ale využíváme k tomu službu Amazonu. Jedná se o standardní MySQL, které znáte z klasických webových aplikací, nic speciálního.
Dlouhá léta toto rozložení perfektně fungovalo a výkonově zcela postačovalo, ale právě koncem prázdnin 2018 jsme narazili na výkonové limity tohoto uspořádání a bylo potřeba s tím něco začít provádět.
V první řadě jsme si tedy připravili bitevní plán:
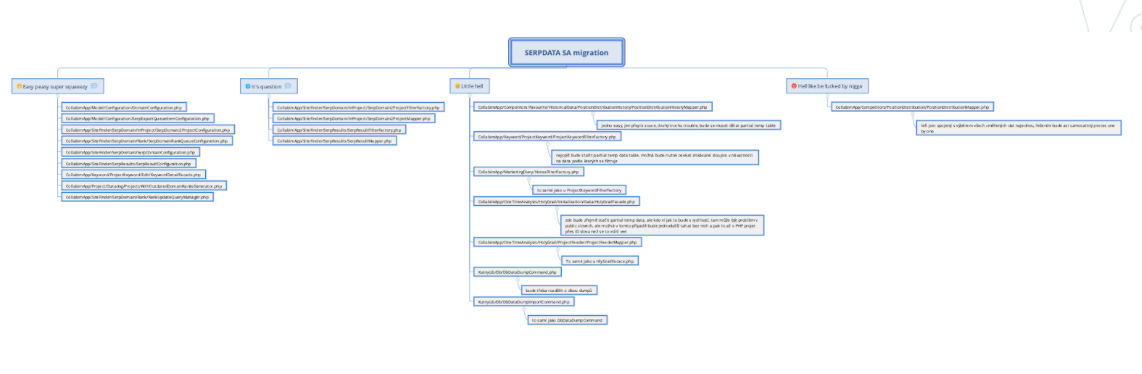
Nejednalo se o nic jiného, než o jednoduchou myšlenkovou mapu v systému XMIND, který zobrazoval veškeré kontrolery (ovládací části naší aplikace) a ty jsme rozdělili celkem do 4 skupin a ohodnotili náročnosti úpravy a revize pro nové uspořádání, které by umožňovalo provoz na více serverech.
Byly určeny čtyři kategorie, které v zásadě vyjadřovaly časovou náročnost revize a opravy kontrolerů (odhadovanou):

No a nakonec jsme vybrali jednoho z perspektivních mladých kádrů našeho týmu a tento úkol mu zadali.

Protože se jedná o klučinu velmi šikovného, který na svůj volný čas již dávno rezignoval a v podstatě pracoval nonstop pouze s přestávkami na spánek a provádění činnosti, kam chodí i králové sami, šlo to jako po másle. No a za jednoduchých a necelých 52 hodin bylo hotovo a připraveno k prvnímu nasazení na produkční servery.
Ano čtete správně, jako většinu věcí na Collabimu, proháníme nové věci rovnou bojem a testujeme na reálný uživatelích. Těžko můžete ladit rychlostní odezvu aplikace bez reálných uživatelů. Vše máme samozřejmě vždy pokryto systémem SENTRY, který nám okamžitě hlásí jakékoliv chyby, které uživatelé mohou dostávat a eliminuje tak značnou část rozdurděných uživatelů na naší podpoře. Současně s tím máme vždy připravenou originální větev aplikace (verzi), kterou jsme schopni během jedné minuty nasadit zpět na produkční servery a tím vzít případnou chybu rychle zpět.
No a jak vypadá nové schéma tedy nyní?
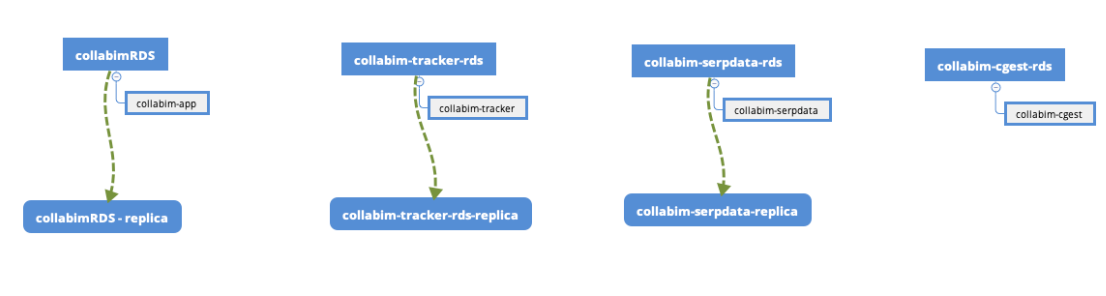
Na obrázku vidíte, že počet serverů se z 1 rozrostl na 7 (což se velmi neblaze dotklo naní portmonky, ale co bychom pro naše uživatele neudělali, že). A to z toho důvodu že vznikly čtyři oddělené servery, které mají svůj vlastní účel a jsou určeny čistě pro každou naši aplikac. Navíc tři z nich, které považujeme za kritické jsou doplňovány vlastní replikoum, která slouží nejenom pro čtení a tím páden i rychlejšímu odbavení uživatelů, ale také jako real-time backup kritických dat. Jako vedlejší bonus jsme tedy získali další úroveň zálohování.
No a na výsledek se již můžete podívat na tomto grafu níže:
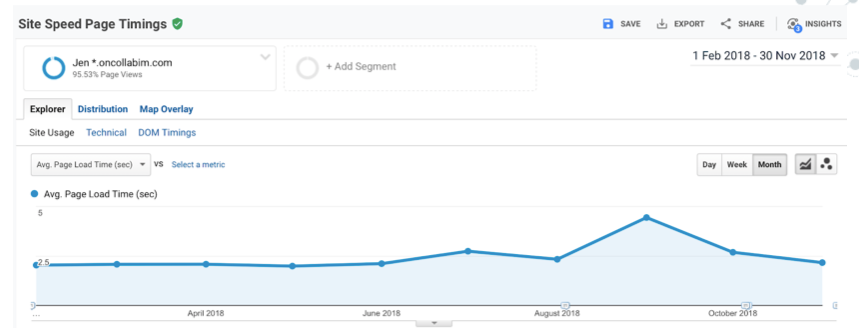
Podařilo se nám dostat z časem odezvy aplikace pod úroveň únorových časů, kdy jsme v podstatě v naší aplikaci měli o 30 procent uživatelů méně než dnes. Naše práce tím samozřejmě neskončila – aktuálně se totiž věnujeme přípravě kompletně nové aplikace, v rámci které je rychlostní odezva jednou z priorit, na kterou se zaměřujeme. Zrychlení současné aplikaci jsme tak považovali za dostatečné mohli jsme opět pokračovat v práci.
Rád bych zde ještě zmínil i technologický upgrade monitoringu, který se nám v rámci tohoto přepisu povedl. Díky rozdělení MySQL serveru (ne díky samotnému upgradu, ale získanou odvahou při migraci serverů) jsme získali možnost nasazení MySQL Performance Insights, které AWS RDS nabízí. Jedná se o pokročilý monitoring databáze, který nám ukazuje nejenom počet procesů které aktuálně databáze vytěžuje (což je základní standardní metrika MySQL), ale zejména přímo zátěž databáze, což je obdoba hodnoty load, který většina systémových administrátorů u svých serverů sleduje. A tedy počet procesů, které čekají ve frontě na zpracování.
Díky tomu jsme schopni mnohem rychleji odhalovat jakékoliv výkyvy v činnosti naší databáze a také ekonomicky kormidlovat počet serverů, které jsou potřeba (v době psaní tohoto článku již jedeme jen na 5 serverů a dále optimalizujeme).
Tuto hodnotu kterou AWS RDS nazývá Sessions si také posíláme do monitoring a systému Datadog, kde máme na tyto výkyvy nastaveno upozornění pomocí SMS a e-mailu. Jakmile tedy dojde ke zhoršení odezvy databázového systému a mohl by to pocítit uživatel, okamžitě o tom ví náš technický dohled.
Na MySQL Performance Insights (pokud tedy používáte AWS) se určitě doporučuji podívat, protože hodnota sessions není samozřejmě jediná věc kterou dostanete, to je pouze vrchol ledovce.
Pod kapotou se totiž skrývá perfektní přehled všech procesů které zrovna v databázi běží, které čekají na odbavení a podobně. To lze samozřejmě vykoukat i z klasického MySQL logu, jenže ruku na srdce – kdo to dělá, dokud není opravdu potřeba. Naproti tomu tuto statistiku lze rozklikávat a využít tak například během deploye nové verze aplikace či si je samozřejmě nechat vytahovat do alertovacích systémů (AWS CloudWatch nepoužíváme).
No a co se z tohoto článku odnést?
- Lidi jsou drazí, stroje ne
- Lepší je více DB než jedna, trochu lépe se rozkládá zátěž
- Replika je super záloha a ještě k tomu může sloužit k READ operacím 😀
- Na AWS se to fakt nakliká
(replica za méně než minutu, kdo z vás to má?) - Monitorujte QUEUE DEPTH, ideálně LOAD procesů (Sessions)
Do budoucna máme v plánu ještě přejít na kompletní automatiku přepínání mezi master a slave databází (replika) a to pomocí systému redis, který umožňuje uchovávání si záznamu s TTL, čili možnosti velmi jednoduše poznamenat si, kdy např. uživatel naposledy něco vložil do systému a po dobu kdy se synchronizuje master -> slave – mu nabízet pouze čtení z masteru .
Tím docílíme absolutního vykrytí jediné nevýhody tohoto řešení a to že existuje nějaká určitá latence mezi hlavním záložním serverem (replikou) V praxi pokud si uživatel vloží například nové klíčové slovo, nemusí ho hned po refreshi okamžitě vidět v seznamu svých klíčových slov a je potřeba ještě jeden refresh .
Nutno říci, že latence se na AWS dle našich zkušeností a velikosti naší databáze (hlavní cca 350 GB) pohybuje na úrovni 0 milisekund.
Pouze v několika málo okamžicích během dne (statisticky řekněme dvakrát za den) se tato latence zvýší na cca 15 milisekund, což je stále méně než trvá refresh stránky. Takže tyto problémy zmíněné výše nepozorujeme.
Pokud jste dočetli článek až sem – klobouk dolů a zasloužíte si určitě lízátko. Můžete si ho jít bez obav koupit!
