
Článek původně vyšel na autorově webu
Webinář zdarma: Jak na sociální sítě, aby to mělo skutečně návratnost?
Právě za chvíli začíná náš webinář zdarma, ve kterém vám ukážu, proč 97 % podnikatelů dělá na Facebooku chyby, kvůli kterým prodělávají peníze a jak se těmto chybám vy vyhnete. Tak honem, ať vám to dnes neuteče!


S3 – Simple Storage Service je na první pohled jedna z nejjednodušších služeb od AWS, ovšem věděli jste, kolik toho nabízí? Co vše se dá vykouzlit?
Je jednou z prvních služeb Amazonu. Jak je řečeno v názvu, je to jednoduché cloudové úložiště, ale umí toho mnohem víc, než by člověk čekal. Pojďme se na to podívat.
Trošku teorie, nebo spíš tedy co S3 má a nabízí, ale v rychlosti 🙂
Jak říká sám Amazon “Secure, durable, highly-scalable cloud storage” — tedy bezpečné, spolehlivé, škálovatelné a také neomezené. Je to objektové(1) úložiště, které nám umožňuje ukládat soubory(2), v zásadě key-value store, kdy každý objekt může mít až 5 TB za cenu přibližně 8 haléřů za GB na měsíc (+ něco málo ze requesty). Soubory jsou uloženy v Bucketech(3) s univerzálním namespacem(4). Má read-after-write consistency pro nové objekty, ale už jen eventual consistency pro změny a mazání (5). 99.999999999% durability a 99.99% availability. AWS ekosystém (používání IAM). REST style HTTP (+ SOAP) interface. Navíc S3 může sloužit jako HTTP server sám o sobě.
(1) — každý objekt má klíč, data/hodnotu, číslo verze, metadata a ACL
(2) — jen na soubory, nejde tam třeba nainstalovat OS
(3) — jde vlastně o mojí podsložku, kterou na AWS mám
(4) — název Bucketu musí být unikátní globálně
(5) — když něco vložím, hned můžu číst, když to ale updatnu nebo smažu, tak to může chvilku trvat (většinou ale < 1s)
Tiery
Co jsem hodně dlouhou dobu nevěděl a překvapilo mě, tak S3 má víc tierů. V základu operujeme s klasickou S3, ale vedle toho je ještě S3-IA (infrequently accessed), kdy se účtuje méně za storage, ale víc za přístupy, tedy hodí se tam, kde chceme mít stejnou spolehlivost, ale zároveň k datům nepřistupujeme tak často. Pak trošku víc extrémnější S3-Reduced Redundancy Storage, který trošku osekává durability objektů a má horší odolnost vůči současnému selhání více datových center (Concurent facillity fault tolerance)- tedy hodí se například na data, která se dají znovu vygenerovat, nebo jejich ztráta nebolí (náhledy, vodoznaky, …).

S3 tiers overviewVedle toho pak ještě stojí Glacier, což je spíš archiv než storage. Glacier je neskutečně levný (cca 10× než S3-standard), každý vhozený archiv může mít až 40TB, ale na jeho vyzvednutí je potřeba 3–5 hodin.
Životní cyklus Bucketů
Pro jednotlivé Buckety můžeme nastavit jakýsi životní cyklus (lifecycle). Bucket (nebo jeho část) má určitá pravidla pro přesuny mezi jednotlivými typy storage. Nastavení je ukázáno na obrázku níže a najdeme ho v Bucket properties > lifecycle.
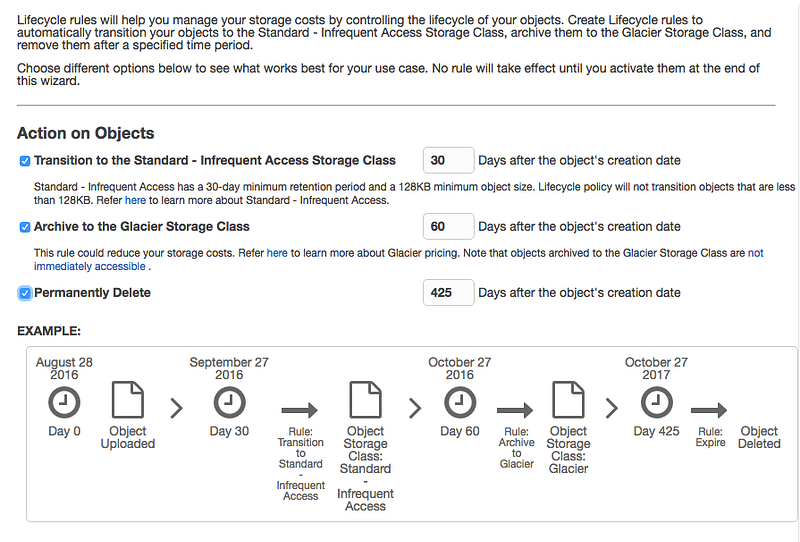
Jak je vidět na obrázku výše, dá se třeba jednoduše říct, že se objekt má po 30ti dnech přesunout do IA, po dalších šedesáti do Glacieru a po dalších 425ti úplně smazat. Je to hodně volitelný, až na pár neduhů(1), ale dá se to vymyslet parádně. Např. u nás takhle ukládáme access logy a sami se nám mažou. Stačilo jen párkrát kliknout. Tyhle pravidla se dají nastavit buď na celý Bucket a nebo třeba jen na podsložku.
(1) — pokud mám nastavenou transition to IA, pak glacier jde nastavit až 30 dní po, když ne, pak klidně hned druhý den.
Verzujeme
S3 nabízí možnost zapnout verzování. Tudíž jednoduše můžeme mít všechny verze daného objektu (včetně jeho smazání, kdy to vlastně vytvoří jen delete mark)(1). Jakmile ale jednou verzování zapnu už nejde vypnout, můžu ho jedině pozastavit (suspend). Verzování se taky dá integrovat s bucketovými pravidly. Navíc ještě můžu zapnout MFA pro mazání, dobrý ne?

(1) — platí se storage za každou revizi. Např. mám objekt co má 1GB, 10x ho upravím bez změny velikosti => platím 10 GB storage.
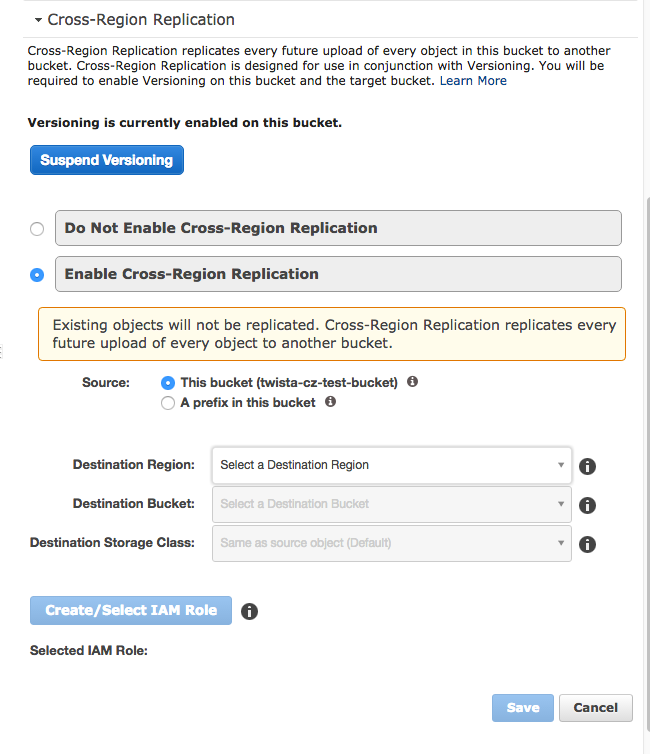
Replikace
Když tedy mám verzování zapnuté, můžu jednoduše kliknout a můj Bucket nechat automaticky replikovat do jiného regionu. Například nahraji-li něco do Bucketu ve Frankfurtu, AWS mi to hned hodí například do Oregonu.
Eventy
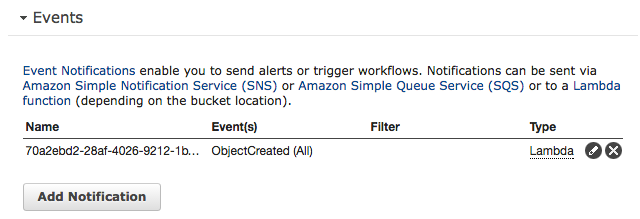
Další ze super věcí je ta, že si můžu na určité události, které se stanou, nastavit event. Událostí je například, pokud se vytvoří nový objekt (nahraju nový soubor) a eventem pak může být notifikace v SNS (Simple Notification Service), SQS (Simple Queue Service) a nebo Lamda (serverless) funkce. Use case v jakém ho používáme je, že necháváme logy z ELB (Load Balanceru) ukládat do S3. V momentě, kdy ELB uloží log, S3 samo zavolá funkci, která ho projde a data uloží do log-storage, kterou máme mimo AWS. Dalším krásným příkladem může být například, že při uložení obrázku funkce sama vytvoří náhledové obrázky.
Další možnosti
I přes zajímavý výčet je tu ještě pár drobností, které mají spíš specifický use case. První z nich je to, že můžeme mít na Bucketu práva pro přístup a to přímo nastavená jako politiku a nebo jako ACL. Hodí se ale spíš, když už trošku víc pracujeme s ostatními službami.
Můžeme také nastavit logování veškeré aktivity (access log) do jiného Bucketu a v neposlední řadě taky šifrování dat.
Bude tu asi ještě pár věcí, které jsem nezmínil a nebo na ně zapomněl, každopádně tyhle mi přijdou nejzajímavější. Doufám, že se článek líbil. Případné otázky rád zodpovím v komentářích. Díky za pozornost!
