
Článek původně vyšel na autorově webu
Webinář zdarma: Jak na sociální sítě, aby to mělo skutečně návratnost?
Právě za chvíli začíná náš webinář zdarma, ve kterém vám ukážu, proč 97 % podnikatelů dělá na Facebooku chyby, kvůli kterým prodělávají peníze a jak se těmto chybám vy vyhnete. Tak honem, ať vám to dnes neuteče!


Nějak nám za poslední dobu narostla práce a nebyl čas moc publikovat, tak jsem si říkal, že něco zkusím sesmolit. O Ansiblu určitě ještě vyjde pokračování (mimochodem, mluvil jsem o něm na WordPress weekendu — wpweekend.cz :))
Teď tedy k tématu. S klukama už přes rok a půl děláme na jednom zahraničním startupu, což je vlastně taková automatizační platforma, kompletně v Pythonu a běžící v AWS. Tak jsem si řekl, že zkusím dát trošku dohromady co a jak používáme a jaké máme zkušenosti.
S AWS jedeme od začátku a zkusili jsme hodně jejich služeb, i když hodně jsme jich po čase přestali používat a nahradili vlastními. Základ nám tvoří banda EC2 instancí (= VPSka), které dokážeme v řádu sekund vytvořit skrze jeden dobře mířený playbook.
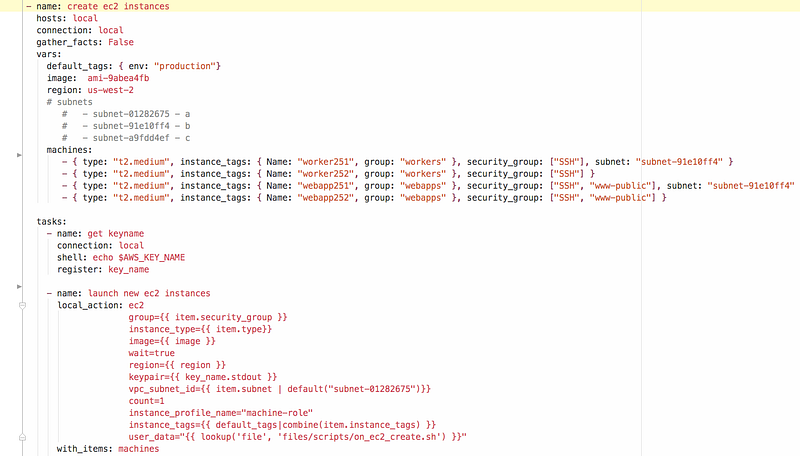
Pak už jen pustit další sadu, která nám nainstaluje vše co je potřeba, od databáze, přes message queue až po webservery. Vše v jednotkách minut.
Vše se snažíme budovat tak, abychom neměli žádný SPOF a Ansible nám umožňuje nasazovat nové služby během pár minut v případě nouze, nebo jen tak na testování. Je sice pár míst, kdy to není ještě 100%, ale to doufám brzo vylepšíme, ostatně je to jeden z long term úkolů co máme 🙂
Na Ansiblu nejedeme od začátku, co to děláme, naopak. Když jsme začínali, tak jsme koketovali s Elastic Beanstalkem, což se nám moc neosvědčilo. Idea vypadá krásně, ale to provedení nebylo ono — vlastně jsme skončili s tím, že jsme měli dlouhý shellscript (s pár výhodama, jako jsou nějaké sekce, což asi furt nedokážu ocenit), který se nějak sám spouští a deployment byl složitější (EB používá nadstavbu nad gitem, takže jde o nějaký magický příkaz a celé mi to přijde jako magie) a celkově jsme z toho neměli dobrý pocit. Nakonec kolega přišel s Ansiblem (ten si dokážu představit, že by krásně fungoval s EB, ale ještě jsme necítili potřebu to zkusit a nahodit, protože nám to teď funguje krásně), což bylo ze začátku trošku větší bariéra, nicméně po čase jsem za to hodně rád. Šetří nám hodně času a hlavně starostí, prostory pro chyby při nasazení služby nebo nové verze tak minimalizujeme na minimum (deploy je vlastně jen `make deploy` a vše je hotovo). Další z výhod je, že nasazení automatického deploye z circlu je doslova pár příkazů.

To by bylo k EB, ze služeb, které jsme používali můžu ještě zmínit SQS (Amazon Simple Queue Service). To bylo ze začátku super. Jednoduché nasadit a v pythonu výborná podpora skrze knihovnu Boto, navíc vše fungovalo krásně a bezstarostně. Ovšem po čase jsme zjistili, že se občas stane, že zpráva dorazí třeba až za víc než minutu (WTF?) a myslím, že ještě pár dalších nedostatků bylo — tedy opustili jsme SQS a nasadili server s RabbitMQ. Nedávno jsme ji nahradili Redisem, ale to je asi na jiný vyprávění — Redis nám funguje líp s Celery 🙂
Asi poslední ze služeb, co jsme používali a implementovali je DynamoDB. Píšou, že je fast a flexible, no my jsme měli problém s tím druhým. Nevím, jestli je to problém implementace driveru, ale flexible nám to nepřipadalo. Pamatuju, že jsme měli problém s hledáním podle různých polí. Dalo se snad hledat jen podle indexu, kdy mohl být jeden index na kolekci + pár range indexů a v podstatě mi přišlo, že nám to házelo klacky pod nohy. Nakonec jsme přešli na MongoDB, který nám přijde super hlavně proto, že využíváme často GEO based query-n. V podstatě nám produkce běží na db, kterou máme jako službu, plus máme separátně cluster s hodně korekčními daty.
Jak jsem nakousl v poslední větě, děláme s adresami a věřím, že by to vydalo na sérii článků, protože člověk jen žasne, co vše je možný a vlastně kolika adresami je možné jednu adresu zapsat.
Addressing is an art.
Abych se zas vrátil po odbočce k AWS a jejich službám, furt je jich tu pár, které využíváme a nedáme na ně dopustit.
Už jsem párkrát zmínil EC2, což se navenek tváří jako klasická VPS. Jako je, ale nabízí hodně věcí navíc – od nastavení security group (skupiny s oprávněním, které explicitně říkají, jaké jsou povolené in/out porty) až po škálování, což je (imo) gró cloudu.
Škálování
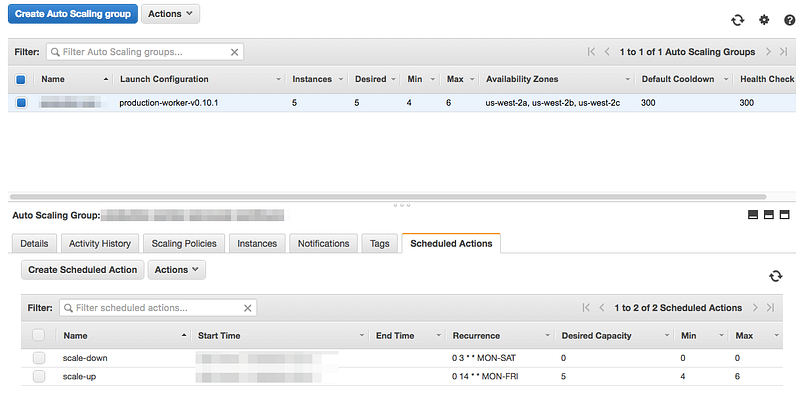
Škálování se řeší všude jinak a (imo) strašně záleží na tom, jaký je obecně stack. Nám v tom (zase) ulehčuje trošku Ansible. Ze začátku bylo trošku těžší to uchopit a určitě ještě nemáme perfektní set-up, každopádně to aktuálně krásně funguje aspoň v měřítku, co potřebujeme a věřím, že se brzo přiblížíme ideálu. Říkali jsme si, že by bylo fajn využít Spot instance (jsou to vlastně nevyužitý servery AWS, který dává za o dost lepší cenu, nicméně je může kdykoliv shodit).
Vytvořili jsme si tedy Launch Configuration, která říká, jaký typ mašiny, za kolik (maximální částka za hodinu běhu) a s jakým nastavením bude běžet. Důležitou věcí je to, že člověk může specifikovat tzv. user-data, což je vlastně start-up script, který se pustí po nastartování. Ten script je klasický shell, který v našem případě jen stáhne Ansible, naklonuje repozitář a spustí set-up — easy. LC si verzujeme v repozitáři (semver), kde máme všechny role/playbooky pro správu (pro tyhle věci je super si vytvořit oauth token na GitHubu).
Druhou částí je pak AutoScaling group. Je to vlastně výčet pravidel, který říká, jak, kdy nebo podle čeho je potřeba kolik serverů. V našem případě říkáme, že v pracovní den, od rána do večera chceme dalších 5 serverů (které se díky LC sami po spuštění nainstalují) a jinak nic. Dají se tam samozřejmě nastavit pravidla v závislosti například na vytížení serveru, s čímž si aktuálně hrajeme, ale ještě to není prod-ready 🙁
Abych se nezasekl jen na popěvku EC2 a věcí okolo, určitě ještě (hlavně jako vývojáři) používáme ELB (Elastic Load Balancer). Mezi hlavní výhody podle mě patří, že nijak nemusíme řešit certifikáty přímo na mašinách (např. webserver), ale dáme je prostě za LB, kde si certifikát klikneme na 2 kliknutí a mašinu strčíme za. Výhoda je taky, že si konkrétní mašiny můžu hezky jednoduše naklikat a nebo na to použít už hotový Ansible modul.
A poslední co dneska jmenuju, je AWS Lambda. Jde vlastně o spouštění funkcí v cloudu. Dokonce by se dalo říct, že se někam nahraje kód a když přijde požadavek, tak se jakoby nastartuje server, zpracuje se požadavek a server se vypne. Je to určitě věc, kterou bychom rádi využívali víc (rozuměj na všechno), ale máme docela problém se systémovými závislostmi, což jsme ještě nebyli schopni vyřešit (GEOS). Každopádně to využíváme na malý http wrapery, jako třeba slack notifikace — místo zprovozňování serveru máme funkci, která vstup vezme, přeformátuje a přepošle. Takže kvůli 20ti řádkům nemusíme vytvářet webserver, a řešit kam to hodíme.
To by bylo pro dnešek asi vše, rád případně zodpovím otázky, popřípadě bych byl rád za nějaké vaše postřehy 🙂 díky za pozornost
